サバ漢(@sabakan_umashi)です🐟
これは、スクレイピングにとある可能性を見出した1人のサバの物語・・・🐟
有名人の不倫とかどうでもいいから、自分の見たいニュースだけ見たいですね🐟
— サバ漢@ゲーム諸々ごった煮 (@sabakan_umashi) December 3, 2020
最近知ったけどノーコードでもスクレイピング出来るらしいから、それで猫ちゃんのニュースだけ見ていたいですね🐈
自分からの一工夫で少しでもストレスフリー🆓#NoCode pic.twitter.com/MVy97Zazu5
「スクレイピング」をあなたはご存知でしょうか?「Web上から必要な情報を取得し、取得した情報を加工する」というのがざっくりとした定義です。
そして最近ではそのスクレイピングを自動で可能にするWebツールがあるのです!
この記事では、そんなWebスクレイピングツールの1つである「Octoparse」の超簡単な使い方について書いておこうと思います。
後編ではOctoparseでスクレイピングするのに必要なワークフローを設定する方法の続きについて書きます。
前編はコチラ。前編ではOctoparseの概要と、スクレイピングするのに必要なワークフローを設定する方法について書いてます。
⇓
sabakan-playroom.hatenablog.jp
超簡単な使い方、それはつまり「実際に使ってみること」です。
「スクレイピングって気になるけど、プログラミング勉強したことないし。。。」という方も読んでみて下さい!
プログラミング未経験であっても使えます。
実際の使用実例をもとに書いた方が分かりやすいと思うので、実例を交えて書きます。「へえ!こんなものがあるんだ!」、「自分だったらこういう風に使ってみたい!」という気持ちになっていただけたら幸いです。
実例から見る、Octoparseを使ったスクレイピングの方法~ワークフロー設定・続き~

【前編のおさらい】Octoparseでスクレイピング~ワークフロー設定~
前編の続きということで、「ねとらぼ 生物部」というサイトを例に、そのサイトで猫ちゃんのニュース記事を探すことをやってみます。
Octoparseの概要については前編に書いてあるのでそちらを参照してもらうとして、後編ではワークフロー設定の続きを書きます。
前編でも書きましたが、Octoparseのワークフロー設定のコツをもう一度書いておきます。
①人間の動作手順を整理する
②Octoparse上で実際に動作をしながら設定する
ちなみにねとらぼ 生物部で猫ちゃんのニュース記事を探す場合は以下の動作手順です。
⇓
①サイト右上にある検索マークをクリックする。
②検索ボックステキストに、「猫」と入力する。
③画面右にある虫メガネマーク(検索)をクリックする。
④検索結果で出てきたニュース記事を見る。
前編では、上の③の手順までワークフロー設定をしました。後編では④から始めます。
Octoparseのワークフロー設定:続き
「④検索結果で出てきたニュース記事を見る」ということですが、ここで思い出して欲しいのは「スクレイピングツールの目的は特定の情報収集であること」です。
なので実際に1記事ずつクリックしてページを開くのではなく、検索結果一覧が表示されているページで必要な情報を集めます。
今回は、「記事タイトル」「記事URL」「記事サムネイル画像」「見出し文」の4種の情報を集めることにします。
ではまずは、記事タイトルの抽出から。
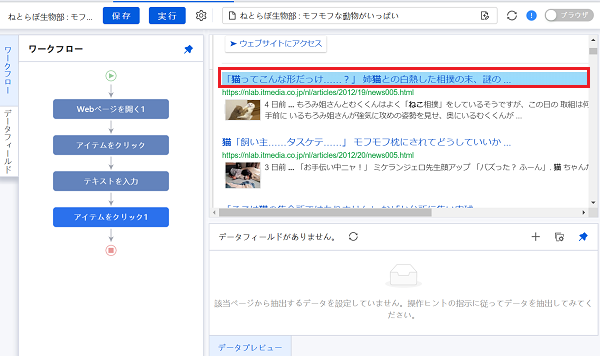
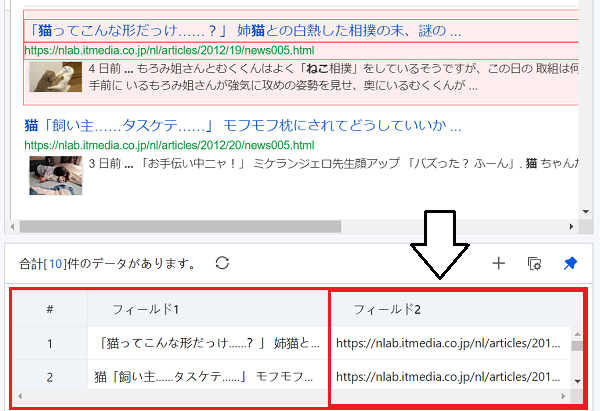
上の画像下部の赤枠内のように、フィールド1に記事タイトルが並んでいれば、記事タイトルの自動抽出設定は成功です。
さて次は、記事URLの抽出です。
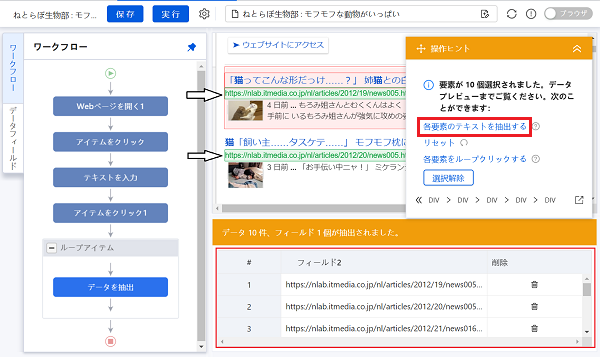
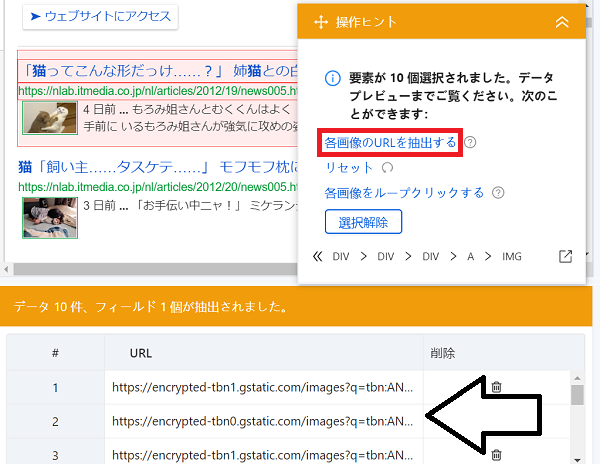
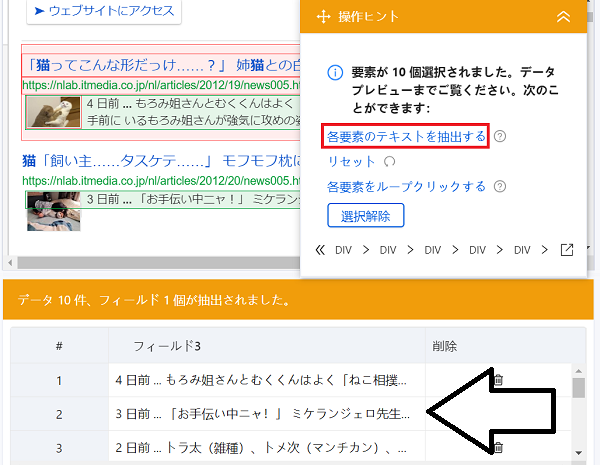
次は記事サムネイル画像と見出し文です。ここも同様の流れでOKです。
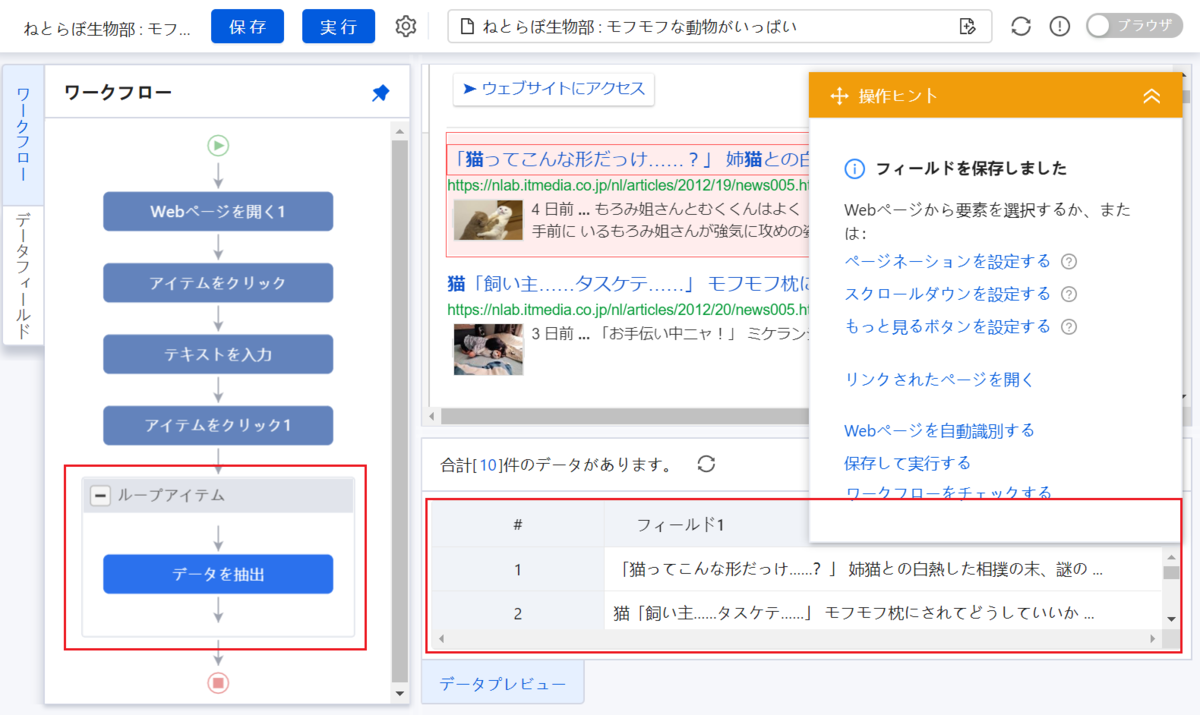
ここまで来たら、画面左にある「データフィールド」というタブをクリックし、「ワークフロー」タブから切り替えてみましょう。
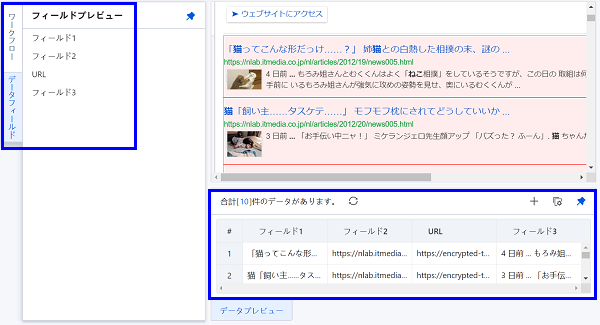
画像下の青枠よりフィールド1は「記事タイトル」、フィールド2は「記事URL」、URLは「記事サムネイル画像」、フィールド3は「見出し文」を表します。
こんな感じでワークフローの設定は完了です。完了したら「保存」を押し、いよいよ抽出を「実行」しましょう。
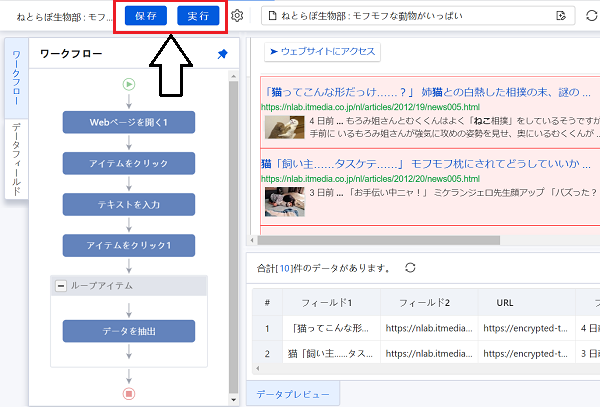
ちなみにワークフロー設定した一連のものは「タスク」と呼ばれ、ダッシュボード内でタスクの一覧を見れます。
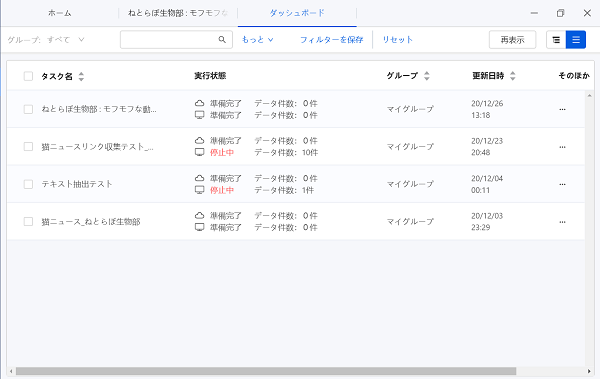
実例から見る、Octoparseを使ったスクレイピングの方法~データの抽出~

さてここから、いよいよデータ抽出をやります。
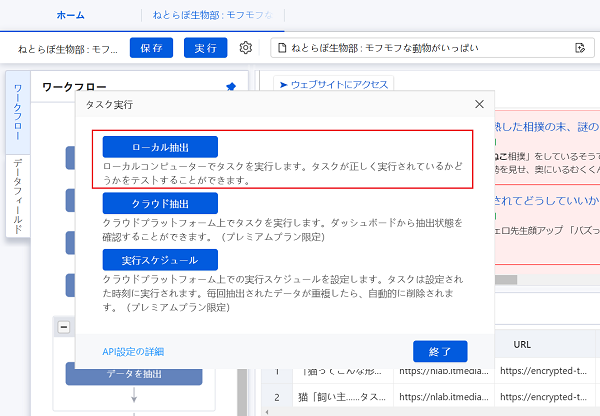
ローカル抽出を選択すると自動で抽出が始まります。
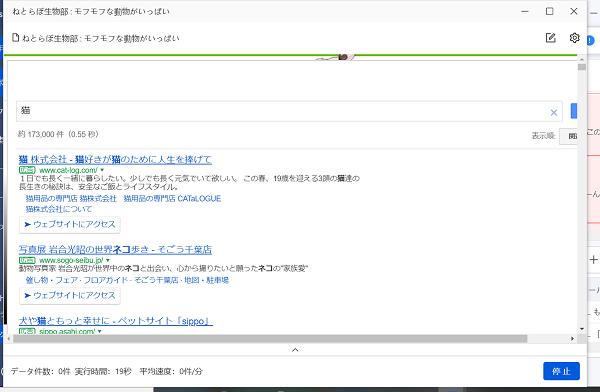
そして、抽出が終わると以下のような画面になります。
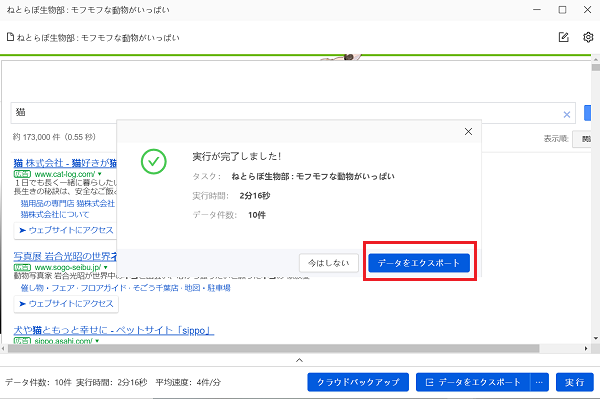
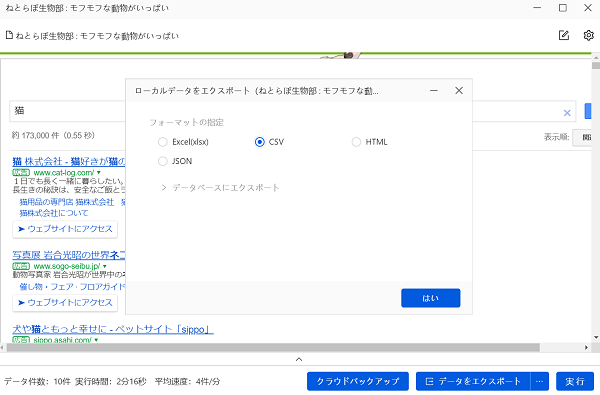
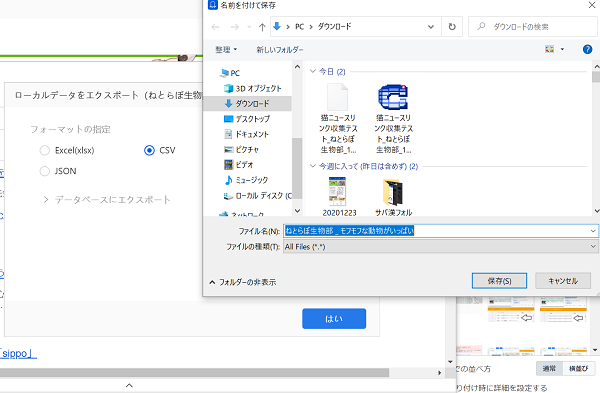
画面見て気づいた方も居ると思いますが、CSVかExcelファイルを読み込めるソフトが必要です。
そして実際に開いてみると以下のような感じです。
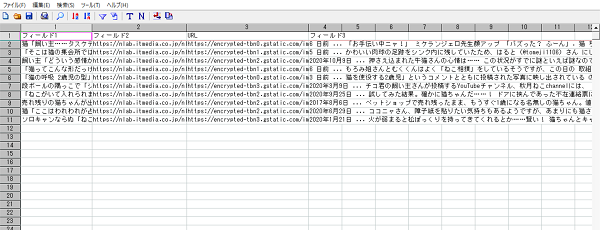
後は自身の好きなように活用しましょう。私は自分で作ったアプリに情報を入れて、猫ちゃんだらけのニュースサイトにしています(笑)
【サバ漢の手作りアプリ🐟】
— サバ漢@ゲーム諸々ごった煮 (@sabakan_umashi) December 23, 2020
猫ちゃんのニュース記事を補填して、明日も電車内で眺めて癒されようと思います🐟
自分の好きな記事を集めるて保管するアプリを作ってみました。
⇓https://t.co/tzLGhuywX1#NoCode #Adalo pic.twitter.com/c7J7zPfHBq
超簡単な使い方解説・後編のまとめ
以上が、Octoparseの一連の使い方です。いかがだったでしょうか?
出来るだけ細かく書いたので「ながっ!?」と感じたかもしれませんが、実際に自分で流れに沿ってやってみると「あっ、こんなもんか。」と思うことでしょう。
興味が湧いた方は、下記公式サイトから「無料トライアル」をクリックし、会員登録をして実際にOctoparseを動かしてみてはいかがでしょう?
⇓
www.octoparse.jp
更にOctoparseのYouTubeチャンネルがあり、そこではOctoparseの操作方法や活用事例を学ぶことが出来るので合わせて参考に!
今回前編と後編で紹介した使い方以外にもOctoparseは用途が色々あるようなので、ここから先は是非ご自身でお試しください。
⇓
www.youtube.com
Octoparseの超簡単な使い方解説・前編はコチラ
⇓
【超簡単な使い方解説・前編】初心者でもすぐ出来る無料スクレイピングツール「Octoparse」 - サバ漢の遊び場兼踏み台
【サバ漢が作った、好きなニュースだけ持ち歩くアプリ】
previewer.adalo.com
【サバ漢のTwitter】
こちらからフォロー⇒サバ漢@ゲーム諸々ごった煮 (@sabakan_umashi) | Twitter